openssh RCE breakdown (CVE-2023-38408) part 1: surprising behaviors
Table Of Contents
This is part 1 in a series where I am going to break down the Qualys security advisory for CVE-2023-38408. It’s a fascinating read on its own, and fairly accessible – the Qualys team is impressive for this as well as their ingenuity and determination making this idea work.
There is a more popular form of tech blogging which tends to offer concise summaries (“read this newsletter every day to stay sharp for your job interviews”) of new technology. This will be pretty much the opposite of that, offering a long-form breakdown of each piece of (relatively ancient) technology involved in the findings. “Learn something old every day,” that’s what I say.
But it’s exciting because as this vulnerability demonstrates, these old tools and concepts are still powerful enough to uncover severe vulnerabilities in tools which are ubiquitous in all forms of tech.
So we’ll be breaking down this exploit writeup, to explore the methods and operating system primitives necessary to reproduce it.
intro to the vulnerability
If you develop in a linux environment, you’re probably familiar with SSH. You use the utility to access other machines, and maybe you use the protocol to access other services, like an SSH key you use to upload your git repositories to github.
This writeup investigated the attack surface of using a forwarded SSH agent, from the perspective of an attacker on a compromised server.
forwarded ssh agent
If you’re using SSH (either the protocol or the client itself) to access resources often, you probably are using an agent. This program runs in the background managing your private keys in memory, and this is convenient because you only need to unlock each key once. After that, your logins to remote servers or git push commands should work without prompting for a password.
When I was first getting started with git and Github on an open source project, I was often working on other engineer's feature branches, and was terrified of accidentally pushing whatever nonsense I had added before cleaning it up. My solution to this was disabling the ssh agent, requiring me to type my password to write to the remote repository. Many would say this is not optimal or convenient, but it worked marvelously (and I didn't mind typing my password a few times a day -- I love typing). Make sure your tools are serving your needs.
Lets say you have your agent running on your laptop which knows about your private key, but you want to do your development on another server (perhaps one with more resources or a specific configuration). You’d still want to be able to access your Github repositories from this server, but your keys aren’t there. You could copy your keys around, or make a separate set of credentials for each server, but wouldn’t it be nice to tell Github that the same ssh agent allowing you to access the new host is the one which will answer the key challenge? This is achieved by forwarding your SSH agent from the client running on your laptop.
This can be configured across an arbitrary chain of clients, and it’s explained in much more detail in Steve Friedl’s Illustrated Guide to SSH Agent Forwarding. One of the security benefits is that your private key never appears on the wire, and as a sysadmin you’d need to balance that against the risk of an agent getting hijacked via its unix socket on a multitenant system.
But public keys aren’t the only authentication method you can use with an SSH agent. You can also use smartcards.
ssh agents, smart cards, and prior art CVE-2016-10009
You can use a forwarded SSH agent with a smartcard via the SSH_AGENTC_ADD_SMARTCARD_KEY command, which tells the original SSH client to look for a PKCS#11 provider, the cryptographic protocol used by smartcards (if it has been compiled with ENABLE_PKCS11, which is the default).
For security reasons, this PKCS#11 helper is run in an entirely separate process with a new address space (so it’s not sharing the address space with loaded private keys). But here’s the catch: the remote server calling the agent (or chain of agents) needs to specify the provider the agent should load. In CVE-2016-10009, Jann Horn discovered there was no check on this provider, and any arbitrary library could be specified as the PKCS#11 provider.
Since OpenSSH implements this functionality with dlopen(), this amounts to arbitrary code execution under two conditions: you’re accessing a malicious remote SSH server, and the attacker has a way to guarantee the location of some malicious code on the victim’s machine (ie. your laptop).
OpenSSH fixed this bug by enforcing an allowlist on libraries that could be considered providers by the ssh-pkcs11-helper executable, and this significantly narrowed the surface available to the Qualys researchers.
mechanism of the vulnerability
So Qualys researchers saw a process responsible for authentication being fed an (almost) arbitrary library by a (possibly malicious) remote server and thought: there’s gotta be some way we can take advantage of this right? But it wouldn’t do anything unless the library was a “system” library (in /usr/lib or /usr/local/lib, presumably these have been vetted by the admin of the system), and if you specify a library not meant for this procedure it just gets closed. They tried to defeat this allowlist, unsuccessfully. So what’s the path forward?
Well it’s not quite true that it “doesn’t do anything” when a library is loaded. Even though a library installed in a system location is probably there for a well-known reason, most libraries aren’t meant to be dlopen()ed (and then immediately dlclose()) by any random process, which is sort of what happens when the agent is given a valid system library which isn’t a PKCS#11 provider.
So the question becomes: given a process which will be instructed to load an arbitrary (non-malicious) system library, what persistent changes can occur to the address space of the calling process? These are referred to throughout the write-up as the “surprising behaviors” and Qualys found 4:
- It can make the process stack executable.
- It can register a signal handler which it forgets to unregister when the library is
dlclose()ed. - It can crash raising a signal (such as SIGSEGV because of a null-pointer dereference)
- It can simply remain loaded in the address space of the process, never being unloaded, permanently resident in the memory mapping of the process.
You can probably start to see the shape of the initial idea:
- load a library that makes the stack executable (side effect #1), then
- load one that registers a signal handler (side effect #2), then
- load a library which will not be removed from the process address space by the loader, replacing the unmapped signal handler’s code (side effect #4), and then
- load a library which raises the signal whose handler was registered in step 2, executing code from step 3’s library which is still resident in memory and hope that the library from step 3 jumps into executable stack. If they could find a combination of libraries which achieve this, it would just be a matter of storing a shellcode in the stack somewhere.
So the researchers took a common Ubuntu installation, installed every package offered by the package manager, and started recording which libraries had which effect. This allowed them to then setup a “fuzzing” process where they could identify combinations of libraries with the intended behaviors in the correct order.
Once identified, they sprayed the stack down with 0xcc bytes, which generates a specific interrupt signal to find which combinations would jump execution to the stack.
return-oriented programming
The concept of executing arbitrary code using only code that’s already on the device is sometimes known as “return-oriented programming,” due to the behavior of a “return” from a function being subverted. A return typically consists of a pop plus a jmp instruction, bringing execution back down to wherever the returning function was called from. And if we overwrite the address of that caller on the stack, we can take execution to wherever we’ve stored malicious code.
But ROP techniques are generally meant to overcome “NX”, which is the “no-execute” bit in the memory management unit of the CPU. This bit marks each memory page as allowed or disallowed from code execution. In the original Qualys idea, they overcame this already by loading an “execstack” library first. And instead of a traditional ROP technique of analyzing the binary for “gadgets” which would allow overwriting the return address, they had to rely on a library being loaded in an unfamiliar environment to fail and jump execution into the stack.
This is a fascinating line of research at the intersection of application security and reverse engineering, and if you read this far and decide you’re more interested in ROP, you can ROP ’til you drop at ROP Emporium.
Although the analysis employed by the researchers relied on some ROP-based concepts, this vulnerability can be more accurately modeled as a use-after-free.
use-after-free
This is another whole class of vulnerability you can read about elsewhere and I won’t dive too deep here. But if the mechanism above doesn’t make sense, let’s look at a common proof-of-concept for such a vuln.
#include <malloc.h>
#include <stdio.h>
typedef struct function{
void (*func_ptr)();
} ptr;
void one() {
printf("This is function one \n");
}
void two() {
printf("This is function two \n");
}
void main() {
ptr *s1 = malloc(sizeof(ptr));
s1->func_ptr = one;
s1->func_ptr(); // Prints "This is function one" right?
free(s1);
ptr *s2 = malloc(sizeof(ptr));
s2->func_ptr = two;
s2->func_ptr(); // Prints "This is function two" right?
s1->func_ptr(); // So what happens here?
}
If you compile and run this, you’ll see that it prints the following:
This is function one
This is function two
This is function two
So the last call to s1->func_ptr() calls two() even though we never assigned s1->func_ptr to the address of two!
You can understand this without all the C by imagining two pointers walk into a fancy restaurant.
s1: I’d like some memory please.
allocator with a towel over his arm: of course, you can find your memory at0xfeedbeef.
s1: thank you, I will set the memory there to point to functionone.
allocator: very good, sir.
s1: okay I’m done with it, you can have it back.
allocator: of course, sir. have a great day.
[enter the s2 pointer]
s2: I’d also like some memory please.
allocator: very well sir, we just got some in from a previous guest who is no longer using it. Feel free to use0xfeedbeef.
s2: I literally don’t care about any of that. I’m going to set that memory to point to functiontwo.
allocator: as you please, sir.
s1 (drunk in the parking lot): I’m gonna call that function again, where did the waiter say it was? Oh yeah it was0xfeedbeef.
The restaurant metaphor is strained, but this gist is the allocator is smart enough to re-use the memory chunk it allocated for s1 after it’s freed, and relies on you not trying to re-use s1 after that. Confirm this is what’s happening in gdb by compiling with debug symbols and inspecting the pointers with gdb:
gcc uaftest.c -g -o uaftest
gdb uaftest
(gdb) b main # set a breakpoint at the main function
(gdb) run
(gdb) n # hit enter until the next line shown calls `s1->func_ptr()`
(gdb) p s1 # print s1
$1 = (ptr *) 0x5555555592a0
(gdb) p *s1 # print the contents of memory pointed to by s1
$2 = {func_ptr = 0x555555555159 <one>}
(gdb) n # hit enter until the next line shown calls `s2->func_ptr()`
(gdb) p s2
$3 = (ptr *) 0x5555555592a0 # same address as earlier!
(gdb) p *s2
$4 = {func_ptr = 0x55555555516f <two>}
(gdb) p s1
$5 = (ptr *) 0x5555555592a0 # we never re-assigned s1 so now they point to the same place
(gdb) p *s1
$6 = {func_ptr = 0x55555555516f <two>}
Now using our surprising behaviors instead of s1, we’re loading a library that handles a signal, and instead of s2, we’re replacing that code with a new library which permanently alters the memory mapping of the process, and will hopefully provide a mechanism to jump execution into the stack (where we have stored some shellcode) when it’s triggered. This trigger will happen when the signal is raised. In this context, this last library is sometimes called a “gadget.”
bigger picture
As a small sidebar, I want to talk about another way this class of vulnerability relates to others.
The end goal is to give the victim’s machine instructions smuggled in as data. This is the concept underlying many classes of vulnerability.
- In use-after-free we’re exploiting the way memory is allocated on the heap to redirect execution to attacker-controlled memory.
- In a buffer overflow or “stack smashing” we’re often doing the same thing by taking advantage of stack memory instead.
- In SQL injection, some web form expects a string containing data, and instead we pass it a portion of a SQL query.
- In XSS the DOM is expecting something it can render, and we somehow give it data that tells it to stop the rendering and execute some javascript in the page’s context.
- In what’s being called “prompt injection”, AI chatbots have even been compromised into revealing private information and violating their rules by providing instructions (typically starting with “ignore all previous instructions and…”) when the AI expected some simple request.
Now you can see why projects like Chromium (whose job it is to process input from the web) adopt principles such as the rule of two: don’t write unsandboxed code in an unsafe language which processes untrusted input.
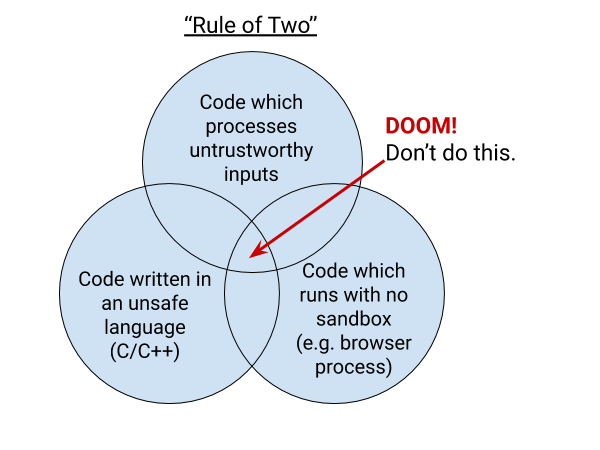
These types of vulnerabilities will still occur, but the intersection is a recipe for high severity.
surprising behaviors
Now that the concepts are clear, you might be wondering (as I was): I’ve never heard of these surprising behaviors, what causes those? I’ve certainly never thought much about which libraries use the NODELETE ELF flag and you’re telling me it can lead to arbitrary code execution on my machine?!
Yes. Let’s break down each one separately.
executable stack
If we wanted to, how could we make a library with an executable stack, and how would we verify that (1) this setting really is set on the library and (2) that it causes any process who loads it to make its stack executable as well?
when such an “execstack” library is dlopen()ed, the loader makes the main stack and all thread stacks executable, and they remain executable even after dlclose().
Who even uses an executable stack? These days typically malware, or so I thought. As it turns out, some ELF libraries require an executable stack: this can happen either because the .note.GNU_STACK ELF header was not set, or it was set explicitly to RWX. But why would we set that, doesn’t that make buffer overflow vulnerabilities a ton more dangerous?
Yes, and GCC will give you a half-hearted warning in this case. As for why it would happen, these days the answer is trampolines. This is discussed in great detail on Chris Wellon’s blog: Infectious Executable Stacks, and I’ll just pull one example from there. Chris writes an integer sorting function which uses a closure to access the outer invert variable from the inner scope.
// trampoline.c
#include <stdio.h>
#include <stdlib.h>
void intsort2(int *base, size_t nmemb, _Bool invert)
{
int cmp(const void *a, const void *b)
{
int r = *(int *)a - *(int *)b;
return invert ? -r : r;
}
qsort(base, nmemb, sizeof(*base), cmp);
}
int main() {
int values[] = { 88, 56, 100, 2, 25 };
intsort2(values, 5, 0);
printf("\nAfter sorting the list is: \n");
for(int n = 0 ; n < 5; n++ ) {
printf("%d ", values[n]);
}
}
The compiler is able to associate the function pointer to the comparator with the lexical environment it was passed from by constructing a trampoline on the stack, where the local variables are stored next to it.
Compile it and see the warning:
$ gcc trampoline.c -o trampoline
/usr/bin/ld: warning: /tmp/ccKWDoEX.o: requires executable stack (because the .note.GNU-stack section is executable)
$ ./trampoline
After sorting the list is:
2 25 56 88 100
You can use the extra/pax-utils util scanelf, or readelf -S <library.so> to confirm the stack setting:
$ scanelf -e trampoline
TYPE STK/REL/PTL FILE
ET_DYN RWX R-- RW- trampoline
So GCC knows that when you use the GNU C dialect closure feature, it needs to link a binary with an executable stack. It doesn’t make you do anything extra to specify this.
Going forward I’m going to use a minimal viable C program just to verify there’s no funny business going on in the link stage.
// nothing.c
#include <stdio.h>
int main() {
printf("hello world");
}
Compile it:
$ gcc nothing.c -o nothing
$ scanelf -e nothing
TYPE STK/REL/PTS FILE
ET_DYN RW- R-- RW- nothing
And now making the stack executable is just a matter of compiling with the -z execstack option.
$ gcc nothing.c -z execstack -o nothing
$ scanelf -e nothing
TYPE STK/REL/PTS FILE
ET_DYN RWX R-- RW- nothing
I know what you’re thinking: sure you can set some static attribute inside the ELF headers which says the stack should be executable, but will this library actually be able to boss another binary around which loads it (and make its stack executable too)?
There’s a few ways to check, but using a debugger is the simplest. We can write a small program to load our “nothing” binary with the executable stack, and check before vs after to see if loading it had any lasting effect.
// dlopen.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <dlfcn.h>
int main(int argc, char** argv)
{
void *handle;
void (*func_print_name)(const char*);
if (argc != 2) {
fprintf(stderr, "Usage: %s library_path\n", argv[0]);
return EXIT_FAILURE;
}
printf("About to dlopen().\n");
handle = dlopen(argv[1], RTLD_LAZY);
printf("Ran dlopen().\n");
int result = dlclose(handle);
printf("Ran dlclose().\n");
}
Compile our “loader” executable with debug symbols:
gcc dlopen.c -g -o dlopen
and compile our “nothing” binary as a shared library instead, with the execstack flag.
gcc -shared -fPIC -z execstack nothing.c -o nothing.so
Now run with gdb
gdb --args ./dlopen $PWD/nothing.so
(gdb) b main
(gdb) run
Now we can use the gdb info proc mappings command to inspect the status of the memory mapped to this process’s stack. Looking for the line labeled [stack], we run it before the dlopen call,
0x7ffffffde000 0x7ffffffff000 0x21000 0x0 rw-p [stack]
Read-write, natch. After the dlopen call,
0x7ffffffde000 0x7fffffffe000 0x20000 0x0 rwxp [stack]
Read-write-execute, expected since we loaded the execstack library. And after the dlclose call,
0x7ffffffde000 0x7fffffffe000 0x20000 0x0 rwxp [stack]
Voila! (Oh no!)
praxis
Running through this one example with a debugger was an easy way to verify what we expected to see. And you should always start this way! Never get too clever too fast.
But once you’ve verified that you know what you’re doing, look at ways to scale the process to your needs. In this case, the Qualys researchers wanted to go through every library on the system that could be loaded by the PKCS#11 helper and check for these effects, and hammer-clicking through each with a debugger wouldn’t cut it.
It turns out this info proc mappings command inside gdb is returning identical contents you’d find mounted by procfs in /proc/<pid>/maps. So if you know the pid of the process you want to inspect, you can always look at this file! And if you want to see how those maps change, it’s as simple as diffing an early version with a later version of the same file. This made it easy for Qualys to look for these changes across hundreds of shared libraries on their target system.
Since we just want to be able to test the individual “surprising behaviors” we should be able to do this without the hassle of invoking the OpenSSH PKCS#11 helper. We can just pretend like we’re the OpenSSH executable by dlopening shared libraries we write, and verify that the maps file in /proc shows the changes we expect.
Let’s modify our dlopen.c from earlier to write out the maps file for its current process before loading a library, and then again after dlclose() , and then diff them to see the effects first-hand.
This borrows the cat_proc method from the step2.c used by the researchers themselves, which ignores lines which are likely to be different in the diff anyway (which are not of interest to us).
// dlopen.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <dlfcn.h>
#include <unistd.h>
#include <limits.h>
static void die(const char * msg) {
fprintf(stderr, msg);
exit(EXIT_FAILURE);
}
static void
cat_proc(const pid_t pid, const char * const in, const char * const out)
{
char buf[PATH_MAX];
if ((unsigned)snprintf(buf, sizeof(buf), "/proc/%ld/%s", (long)pid, in)
>= sizeof(buf)) die("Buffer size didn't match.\n");
FILE * const in_fp = fopen(buf, "r");
FILE * const out_fp = fopen(out, "w");
if (!out_fp) die("Error opening output buffer.\n");
if (in_fp) {
while (fgets(buf, sizeof(buf), in_fp)) {
if (!strchr(buf, '\n')) die("No newlines in file.\n");
if (!strncmp(buf, "Vm", 2) ||
!strncmp(buf, "Rss", 3) ||
strstr(buf, "HugetlbPages:") ||
strstr(buf, "voluntary_ctxt_switches:") ||
strstr(buf, "State:") ||
strstr(buf, "[heap]\n"))
continue;
if (fputs(buf, out_fp) <= 0) die("Error streaming file to output.\n");
}
if (fclose(in_fp)) die("Error closing input file.\n");
}
if (fclose(out_fp)) die("Error closing output file.\n");
}
int main(int argc, char** argv)
{
void *handle;
void (*func_print_name)(const char*);
if (argc != 2) {
fprintf(stderr, "Usage: %s library_path\n", argv[0]);
die("Use the right number of arguments!\n");
}
printf("Writing maps1.\n");
pid_t pid = getpid();
cat_proc(pid, "maps", "maps1");
printf("About to dlopen().\n");
handle = dlopen(argv[1], RTLD_LAZY);
printf("Ran dlopen().\n");
int result = dlclose(handle);
printf("Ran dlclose().\n");
printf("Writing maps2.\n");
cat_proc(pid, "maps", "maps2");
}
Compile this and load our nothing.so library like before, then diff the resulting maps files:
./dlopen $PWD/nothing.so
Writing maps1.
About to dlopen().
Ran dlopen().
Ran dlclose().
Writing maps2.
diff -u maps1 maps2
now shows the following results:
--- maps1 2023-12-25 16:02:15.954942724 -0800
+++ maps2 2023-12-25 16:02:15.958276058 -0800
@@ -17,5 +17,6 @@
7ffff7ff1000-7ffff7ffb000 r--p 00027000 103:03 27921674 /usr/lib/ld-linux-x86-64.so.2
7ffff7ffb000-7ffff7ffd000 r--p 00031000 103:03 27921674 /usr/lib/ld-linux-x86-64.so.2
7ffff7ffd000-7ffff7fff000 rw-p 00033000 103:03 27921674 /usr/lib/ld-linux-x86-64.so.2
-7ffffffde000-7ffffffff000 rw-p 00000000 00:00 0 [stack]
+7ffffffde000-7fffffffe000 rwxp 00000000 00:00 0 [stack]
+7fffffffe000-7ffffffff000 rw-p 00000000 00:00 0
ffffffffff600000-ffffffffff601000 --xp 00000000 00:00 0 [vsyscall]
Now we can see that not only has our executable “nothing” library made the stack executable even after it’s closed, but it also made the calling process split its stack into two. I’m not sure what’s causing this actually, maybe a security feature by only making part of the stack executable?
nodelete
Since we already wrote a script to help us diff the /proc/<pid>/maps files, lets use it to look at this behavior as well. To recap, this “surprising behavior” is that when this flag is set on the shared library, it never gets unmapped from the process address space, even after dlclose().
Let’s try to do the exact same thing with our “nothing” shared library, but set the “nodelete” flag instead of the “execstack” flag. So compiling will look like this instead:
gcc -shared -fPIC -z nodelete nothing.c -o nothing.so
I don’t know of an easy way to look at this flag, but the Oracle linker and libraries guide tells us to look in the ELF file dynamic flags DT_FLAGS_1 section for the 0x8 value which corresponds to DF_1_NODELETE.
Sure enough, we do see this entry:
$ dumpelf nothing.so
[SNIP]
/* Dynamic tag #19 'DT_FLAGS_1' 0x2F28 */
{
.d_tag = 0x6FFFFFFB ,
.d_un = {
.d_val = 0x8 ,
.d_ptr = 0x8 ,
},
},
[SNIP]
If we run our loader script again and diff the maps files
$ ./dlopen $PWD/nothing.so
$ diff -u maps1 maps2
we see the following results instead:
-- maps1 2023-12-25 16:18:03.594949384 -0800
+++ maps2 2023-12-25 16:18:03.594949384 -0800
@@ -10,6 +10,11 @@
7ffff7e3e000-7ffff7e40000 rw-p 0023d000 103:03 27921687 /usr/lib/libc.so.6
7ffff7e40000-7ffff7e4d000 rw-p 00000000 00:00 0
7ffff7f94000-7ffff7f98000 rw-p 00000000 00:00 0
+7ffff7fbf000-7ffff7fc0000 r--p 00000000 103:03 9729605 /home/chris/Projects/CVE-2023-38408/dlopen_read_maps_file/nothing.so
+7ffff7fc0000-7ffff7fc1000 r-xp 00001000 103:03 9729605 /home/chris/Projects/CVE-2023-38408/dlopen_read_maps_file/nothing.so
+7ffff7fc1000-7ffff7fc2000 r--p 00002000 103:03 9729605 /home/chris/Projects/CVE-2023-38408/dlopen_read_maps_file/nothing.so
+7ffff7fc2000-7ffff7fc3000 r--p 00002000 103:03 9729605 /home/chris/Projects/CVE-2023-38408/dlopen_read_maps_file/nothing.so
+7ffff7fc3000-7ffff7fc4000 rw-p 00003000 103:03 9729605 /home/chris/Projects/CVE-2023-38408/dlopen_read_maps_file/nothing.so
7ffff7fc4000-7ffff7fc8000 r--p 00000000 00:00 0 [vvar]
7ffff7fc8000-7ffff7fca000 r-xp 00000000 00:00 0 [vdso]
7ffff7fca000-7ffff7fcb000 r--p 00000000 103:03 27921674 /usr/lib/ld-linux-x86-64.so.2
It works! The library is still mapped into memory even after it’s been closed. There are several entries here which correspond to the different ELF sections of our shared library.
These are both pretty surprising to me, as they are just “dumb” linker flags that anyone could set, and there’s no step in running the binary smart enough to determine that we don’t actually want an executable stack, or we don’t need it to still be mapped after we close the library.
signal handler
We can demonstrate a signal handler in C using more conventional methods… we’re still gonna do it the other way too but let’s show the easiest way first.
// handler.c
#include <signal.h>
#include <stdio.h>
#include <stdlib.h>
void handler(int sig) {
printf("SIGNAL: we got %d\n", sig);
exit(1);
}
__attribute__((constructor))
static void init(void) {
printf("Loading the handler...\n");
signal(SIGSEGV, handler);
}
That registers the handler, and now let’s write a program to throw the SIGSEGV:
// segfault.c
#include <stdio.h>
#include <stdlib.h>
int main() {
printf("This should segfault.\n");
int i = *(int *)0;
return 0;
}
Compile both:
gcc -shared -fPIC handler.c -o handler.so
gcc segfault.c -o segfault
First verify that you will indeed see the segfault when you run ./segfault
$ ./segfault
This should segfault.
[1] 1820419 segmentation fault ./segfault
Great! Now we are going to use LD_PRELOAD to hijack the symbol resolution at runtime with a our handler.so library, which installs our special signal handler!
$ LD_PRELOAD=$PWD/handler.so ./segfault
Loading the handler...
This should segfault.
SIGNAL: we got 11
Brilliant.
When we try diffing our maps files using the previous technique, we will unfortunately find that there is no difference – registering a signal handler does not permanently alter the memory mapping of the process.
$ ./dlopen $PWD/handler.so
Writing maps1.
About to dlopen().
Loading the handler...
Ran dlopen().
Ran dlclose().
Writing maps2.
$ diff -u maps1 maps2
In order to show that a signal handler has been registered and remains associated with the process even after dlclose(), we need to instead look in the /proc/<pid>/status file. Run man proc to see more info about what’s in these files. For our purposes, open our dlopen.c and add the following line under each of the cat_proc calls where we copy the maps files:
int main(int argc, char** argv) {
...
cat_proc(pid, "maps", "maps1");
cat_proc(pid, "status", "status1");
...
cat_proc(pid, "maps", "maps2");
cat_proc(pid, "status", "status2");
}
Our program will now write out status1 and status2 to the current directory, alongside the maps1 and maps2 files from earlier.
Now after we compile and run it in the same way, we can diff those.
diff -u status1 status2
and see one line in the diff:
--- status1 2023-12-25 17:25:48.268312351 -0800
+++ status2 2023-12-25 17:25:48.268312351 -0800
@@ -23,7 +23,7 @@
ShdPnd: 0000000000000000
SigBlk: 0000000000000000
SigIgn: 0000000000000000
-SigCgt: 0000000000000000
+SigCgt: 0000000000000400
CapInh: 0000000800000000
CapPrm: 0000000000000000
CapEff: 0000000000000000
SigCgt stands for “signals caught” and that sounds like what we’re looking for.
interpreting signal masks
We can see that loading our signal handler is changing something in the status of the process, but what does this 0x400 business mean? To find out, we can use the kill command to list all the signals:
kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
In some newer kernels these will already by provided in a list of suffixes (ie. you’ll see HUP INT QUIT ILL TRAP instead), but if the output looks like the above you can get these into a map for your bash-scripting needs like this:
kill -l | sed 's/[[:space:]]*\([[:digit:]]*\)[)][[:space:]]*\([^[:space:]]*\)[[:space:]]*/\1 \2\n/g' | grep -v ' SIGRTM' | grep .
1 SIGHUP
2 SIGINT
3 SIGQUIT
4 SIGILL
5 SIGTRAP
6 SIGABRT
7 SIGBUS
8 SIGFPE
9 SIGKILL
10 SIGUSR1
11 SIGSEGV
12 SIGUSR2
13 SIGPIPE
14 SIGALRM
15 SIGTERM
16 SIGSTKFLT
17 SIGCHLD
18 SIGCONT
19 SIGSTOP
20 SIGTSTP
21 SIGTTIN
22 SIGTTOU
23 SIGURG
24 SIGXCPU
25 SIGXFSZ
26 SIGVTALRM
27 SIGPROF
28 SIGWINCH
29 SIGIO
30 SIGPWR
31 SIGSYS
But all we really need to do for now is convert this mask to binary and reverse it, and count over the number of zeros to find which signal was still being caught when the status file was copied:
echo "obase=2; ibase=16; 400" | bc | rev
00000000001
So you can count to see the 11th bit is set, therefore the process has a signal handler installed for signal #11. which we can see above was SIGSEGV, just like we expected.